Amazon Web Services Feed
Pioneering personalized user experiences at StockX with Amazon Personalize

This is a guest post by Sam Bean and Nic Roberts II at StockX. In their own words, “StockX is a Detroit startup company revolutionizing ecommerce with a unique Bid/Ask marketplace—our platform models the New York Stock Exchange and treats goods like sneakers and streetwear as high-value, tradable commodities. With a transparent market experience, StockX provides access to authentic, highly sought-after products at true market price.”
During StockX’s hypergrowth in 2019, our small group of machine learning (ML) engineers added a Recommended For You product row to the homepage using Amazon Personalize, which ultimately became the top-performing homepage row. This post shares our journey with Amazon Personalize to deliver customized user experiences.
Our marketplace dynamics necessitate surfacing personalized user experiences. Traffic spikes to the site are driven largely by drops—in sneaker and streetwear marketplaces, these are pre-communicated releases of highly-popular, limited edition items. Though the diversity of our customers’ product interests has been rapidly broadening, users still often search for specific hot items from these recent releases. This results in frequent large DDoS-like traffic influxes to our platform, which make backend scalability a top priority. Additionally, our team planned to launch the Recommend For You product row shortly before Black Friday. These factors motivated the need for a robust recommendation engine that can scale, change in real time, and adapt to a moving customer intent.
Three years into our company’s journey, we began prioritizing personalization of the user experience as a core growth objective. Our customer base has been steadily evolving from solely lifetime sneakerheads to include more and more casual and curious users. Thanksgiving weekend offered us the opportunity to drive customer retention by reaching these newer customers with a personalized experience. Despite the approaching 2019 holiday season adding additional constraints to planning, Amazon Personalize empowered us to create highly curated and engaging experiences for our evolving user base in time for the seasonal traffic surge.
Early stages
Our team originally looked at third-party vendors to fill the personalization gap in our platform. However, purchasing an off-the-shelf solution was both costly and inflexible to our unique ecommerce marketplace. These off-the-shelf solutions are often opinionated about all aspects of the ML process. We needed more flexibility than what a third party could offer, but weren’t convinced our problem required a wholly in-house solution.
We next researched building a custom neural network with parity to the Amazon Personalize core recommender, the hierarchical recurrent neural network (HRNN). Although our team was equipped to build the model, we had to take certain confounding variables into consideration: robustness, scalability, and time. We were in a race against the clock to build a quality service to provide a compelling experience for our customers and keep up with holiday traffic. The development time required to tune a custom model, and the uncertainty around inference performance, caused us to enumerate the proper requirements to build an ML microservice. This allowed us to identify which pieces we would build versus buy. Our requirements were as follows:
- Data collection – The first step to building a high-performing recommender is making sure you have the correct tracking on your site. Having explicit evidence about your customers like surveys, ratings, and preference settings is good, but implicit evidence mined from a raw clickstream usually provides a more compelling experience. Collecting this clickstream data is the first step on the journey to creating a functional recommender.
- Data location – After you collect the right kinds of data, the next step is to locate where this data is being housed. For our purpose, we had to locate where our clickstream and product catalog data was housed and gain access.
- Data wrangling and feature engineering – After you’ve discovered all your data sources and storage locations, figure out what pieces of it are useful. This is an empirical, time-consuming process because it’s difficult to know where the algorithm finds signal in your data until you try it out.
- Model development – This step is the most data science-intensive in the development lifecycle. Most teams begin with a prototype in a notebook that solves the business problem then move to an object-oriented solution for model training. This step is interdependent with the preceding step because data availability constrains the set of candidate models.
- Model testing and evaluation – After you have a trained model, you must enable quick sanity checks for qualitative analysis to supplement training metrics. We suggest creating a small visualization application to show what products a user has been interacting with next to what the model recommends. This allowed us to visually inspect the recommendations for different algorithms and hyperparameter settings to compare them empirically.
- ETL development – After you identify the salient features of the data, you should have an automated ETL that extracts the raw data, performs the feature engineering, and puts that data somewhere easily accessible by your production training routine. This step is paramount because subtle bugs in your ETL can lead to garbage in, garbage out failures, which are difficult to detect until visualizing the output at the end of training.
- Backend service development – Wrapping your model inference mechanism with a backend service improves monitoring, stability, and abstraction. This was especially important for us as a bulkhead to protect against the large influx of traffic we expected. We chose a serverless solution in AWS Lambda to wrap the getRecommendations API in Amazon Personalize.
- Production deployment – An automated process such as CI/CD, which trains and deploys new versions of your model, keeps recommendations relevant to your customers. A breakdown in this step means recommendations become stale, which reduces engagement. After you have this piece, your ML microservice is complete.
Building a homegrown solution would have meant developing all eight pieces from scratch. Amazon Personalize has automated feature engineering and model development (Steps 3 and 4) which are undoubtedly the two most time-consuming steps. Using the standard HRNN from Amazon Personalize made sure that a simple dataset with only five columns was all we needed for our use case to start training a proven model used by Amazon itself. Offloading these two steps to Amazon Personalize enabled us to focus on implementing a sturdy ETL, backend, and production deployment system. We also had more time to invest on the visualizations mentioned in step 5, a luxury we may not have been able to afford if we had to develop the full stack. However, this didn’t come without sacrifices—we gave up the ability to tune our algorithms outside of the levers that Amazon Personalize provides.
This understandably led to a debate within our team: do we maintain full control of our model at the cost of high maintenance, or trust in the AWS solution at the cost of full tunability for our users? We put our trust in the expertise of AWS in building enterprise-grade, ML models. Our team foresaw significant risk in the scaling characteristics of an in-house deep learned inference engine. Scaling characteristics for large amounts of traffic is difficult to gauge without investment in load testing, which means more development time. Production deep learning microservices are relatively new and there isn’t a wealth of literature on the topic, which compounds the problem.
Development
After deciding to delegate the recommender’s core model development and production inference scaling to AWS, we began developing with Amazon Personalize and quickly discovered the ease of integrating it into a fully-scalable ML pipeline. The following diagram illustrates the solution architecture.
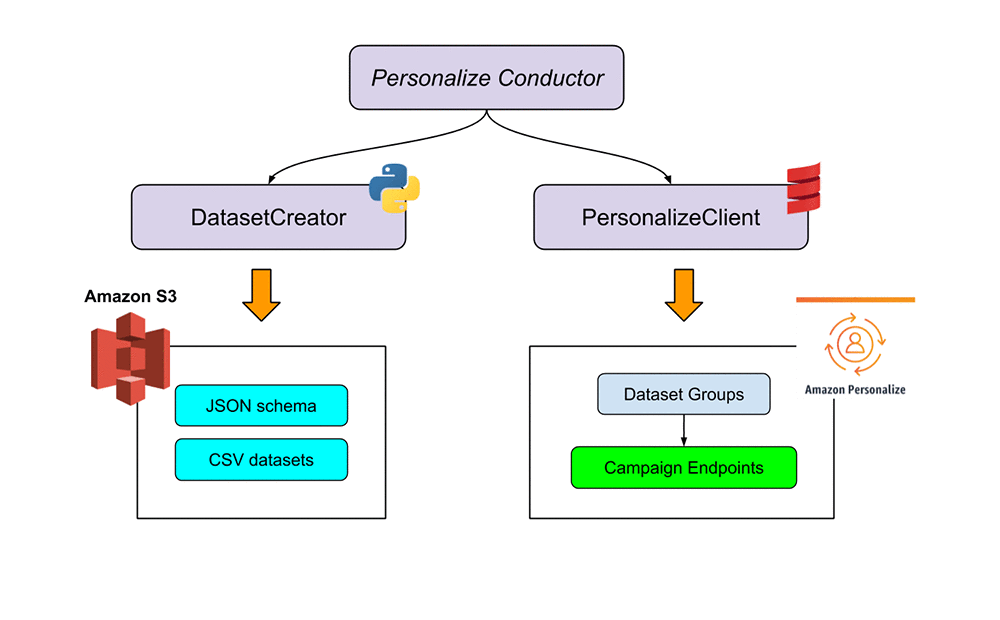
We plugged Amazon Personalize into a two-pronged code base split into dataset creation and Amazon Personalize infrastructure provisioning. This code base fully automates the creation, deployment, and retraining of the Amazon Personalize-powered real-time recommendation engine.
Creating the dataset
Amazon Personalize provides you with a variety of recipes to select based on user characteristics and the specific application of your recommendation engine. Some recipes include the ability to consider user characteristics during model training (such as HRNN-metadata), while others consider only each user’s interactions on the platform and are agnostic to individual characteristics (HRNN). The recipe you select determines how to construct training datasets and how many to provide to Amazon Personalize to train a solution.
We first developed infrastructure for training and testing all three HRNN variations (plain, metadata, and coldstart), and compared results. We didn’t initially find significant improvements in recommendations when adding meta datasets, and discovered the HRNN-coldstart recipe didn’t produce the organic-type recommendations without additional feature engineering development. Although we suspect investing more time in feature engineering for the meta datasets would have eventually led to improved performance, we decided to run with the simpler solution that still provided high-quality recommendations. Each unique use case of Amazon Personalize dictates the optimal recipe selection, and we found that HRNN delivered the ideal balance between implementation simplicity and recommendation quality.
Using the Amazon Personalize HRNN recipe requires providing a single dataset containing user interactions over an arbitrary time span. This interactions dataset contains and defines the training features that influence the core recommender algorithm. For an ecommerce platform like StockX, relevant interaction features could include metrics like product page views, search result clicks, or actions related to completing a purchase.
To build the interactions dataset, we created an automated Python ETL pipeline to query our clickstream data source and product catalog, process the interactions data to extract desired features, and build CSVs formatted for Amazon Personalize ingestion. Because Amazon Personalize natively supports importing datasets from Amazon Simple Storage Service (Amazon S3), creating this automated pipeline was a straightforward process and let us focus primarily on how to select the best recipe and optimal timespan for interactions.
Creating an automated Amazon Personalize infrastructure
We next turned to automating the entire Amazon Personalize infrastructure creation. Although you can manually stand up the Amazon Personalize service exclusively on the AWS Management Console, using the AWS SDK for Java enables full automation and repeatability in the larger recommendation service pipeline. We chose Scala for the client to create the Amazon Personalize infrastructure, which contained the following:
- Dataset groups
- Datasets
- Import jobs
- Solutions
- Solution versions
- Live campaigns
Building the infrastructure on the console is simpler for one-off training, but for a completely automated, repeatable pipeline, using the SDK is crucial.
Strategizing deployment
Most importantly, our Scala client takes on the additional responsibility of arbitrating the production deployment process and ensures no downtime while the recommender model is retraining. As users continue to interact with the platform, it’s necessary to retrain the model to include these new interactions and provide the freshest possible recommendations. Retraining the model with the latest interactions data corresponds to a lengthy service outage when training daily because the campaign endpoint becomes unavailable during this time. Mitigating this with two separate live campaign endpoints (and therefore solution versions) is possible, but costly—even campaigns not serving live traffic incur excess AWS charges.
To solve this deployment challenge and create the most cost-effective microservice, we created a unique deployment strategy centered around an intermediary Lambda function. This function is responsible for hitting the campaign endpoint and serving recommendations to front-end clients. A special dataset group tag (Maize/Blue) is packaged into a Lambda environment variable and indicates which campaign endpoint is currently live and serving production traffic.
On a nightly basis, the Scala client initiates a new training run and begins by checking the production Lambda environment variable for the live dataset group. The client loads the fresh interactions dataset and rebuilds the dormant dataset group, after which it performs a heartbeat check on the endpoint to ensure success. The client then instructs the Lambda function to update its campaign environment variable to point to the new endpoint. Afterwards, the unused Amazon Personalize infrastructure is deconstructed.
In this way, the microservice can effectively retrain the Amazon Personalize model automatically and refresh user recommendations daily without costly redundancies or any service downtime. Additionally, using a Lambda function enables custom metrics tracking and failure monitoring systems that alert you of training issues or campaign endpoint errors. This robust microservice deployment strategy crafted around Amazon Personalize gave the StockX recommendation engine a near-perfect availability during the busiest holiday season in the company’s history. The following diagram illustrates this architecture.

Real-time capability
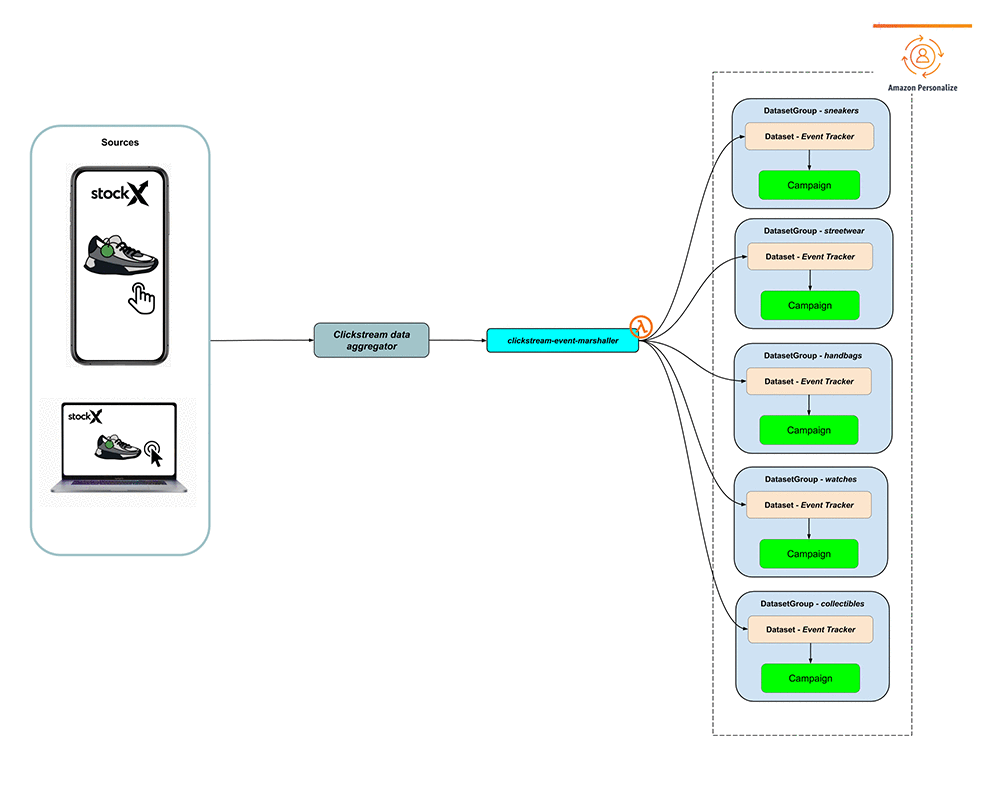
With our training and deployment processes codified, we had one last problem to solve: how to update recommendations as user interest changes between training runs. Amazon Personalize has a simple solution called the event-interactions dataset. We used the Amazon Personalize putEvents API to add clickstream events to our model. The clickstream source pushes events in real-time to a Lambda function, which marshals it into the expected format for Amazon Personalize. These events are added to the dataset and shift recommendations in seconds. The following diagram illustrates this workflow.
Testing and deployment
Our rollout plan has become the standard at StockX—the Recommended For You homepage collection was deployed behind a feature flag instrumented for A/B testing. This allowed the team to safely roll the feature out to 1% of users as an initial canary test. We eventually ramped the test to 60% of users, with 30% seeing the old experience, 30% receiving the personalized home page experience, and 40% exempt from testing. While dialing the feature to larger portions of our customer base, we saw no increase in error rate or latency. We ran the test for 2 weeks.
Even though Recommended for You was the second homepage row, it outperformed the clickthrough rate of our Most Popular row at the top. The Recommended For You collection continues to be our highest performing purchase funnel, percentage-wise. Our overall customer engagement with the homepage increased 50%, which proves that personalizing even one piece of a webpage is effective enough to boost clickthrough of other elements.
Personalization remains a C-Suite strategic objective, with our recommendation engine as the first major key result. Tactical decision-making was made in partnership with our product lead in charge of the product discovery experience. As a unicorn startup, we hypothesized that personalization was important, but this A/B experiment illustrated just how powerful it is. After initial results started rolling in, the question was not whether to personalize, but how to personalize every aspect of the StockX experience. The ML team has always been one of the most data-driven engineering teams at StockX, and this experiment helped show how testable KPIs can make sure we improve the experience in measurable ways.
Conclusion
The team learned a lot about building an ML microservice during this project. The following are some of our key suggestions:
- Integrate early – It’s important to get working demos out early in the lifecycle of your project. Even simple recommendation algorithms can be impressive to stakeholders and help you with resources and prioritization.
- Visualization – Having a visualization tool is essential for testing an ML model. Inspecting raw product IDs as a sanity check is a non-starter; you need images of your recommended products and implicit evidence for the user side by side to evaluate the recommender’s efficacy.
- Ramp up complexity – Amazon Personalize, along with other ML frameworks, has a large breadth when it comes to complexity. We started with the more complex recipes and found it difficult to diagnose strange recommendations. Starting with the plain HRNN recipe allowed us to quickly produce an impressive working example.
- Estimate your costs – ML is expensive. Make sure you have accurate estimates of how much your engineering decisions are going to cost. This isn’t just cloud infrastructure, but also developer time.
- Understand scaling – If you’re building your own deep learning recommender, make sure you understand the scaling characteristics of inference. It’s painful to learn that your home-grown solution can’t keep up with the reality of traffic spikes.
- Do nothing manually – An ML microservice has a lot of moving parts, more so than classical backend services. Automate everything in your pipeline—if there’s one piece of the ETL or deployment process that requires human intervention, consider it a failure. ML engineering is hard enough as is.
Recommended for You was a massive win for both our team and StockX as a whole. We’re quickly learning the potency of integrating ML into all facets of the company. Our success led to key decision-makers requesting we integrate Amazon Personalize into more of the StockX experience and expand our ML endeavors. It’s safe to say that personalization is now a first-class citizen here.
Our team launched the first personalized part of the StockX experience weeks before the largest holiday season we had ever seen. We are proud to say that our microservice had a near-perfect availability throughout thanks to Amazon Personalize.
About the Authors
 Sam Bean is the founding member and leader of the machine learning department at StockX. He is on the constant hunt for harder problems to solve with easier, serverless solutions. Sam is fascinated with the new applications of reinforcement learning and GANs that arise on a near-daily basis. On the side, he is a player and tournament director in the competitive pinball scene.
Sam Bean is the founding member and leader of the machine learning department at StockX. He is on the constant hunt for harder problems to solve with easier, serverless solutions. Sam is fascinated with the new applications of reinforcement learning and GANs that arise on a near-daily basis. On the side, he is a player and tournament director in the competitive pinball scene.
Nic Roberts II is a Detroit-based software developer passionate about machine learning and startups, joining StockX in 2019 after graduating from the University of Michigan. His other interests include innovation in the transportation industry, with previous work on developing autonomous vehicle algorithms and leading a student design team in the 2016 SpaceX Hyperloop Pod Competition. In his free time Nic enjoys traveling, skiing in Northern Michigan, and building his growing sneaker collection.